Learn
Building infrastructure around GPT Assistants (using Google Cloud)
Jul 14, 2024
A unidirectional data flow for chat generated content.
OpenAI’s assistants are an excellent way to encapsulate instructions, which is just what we want for a tool that generates Simily Simulations.
The normal pattern for talking to any chat bot looks something like this:
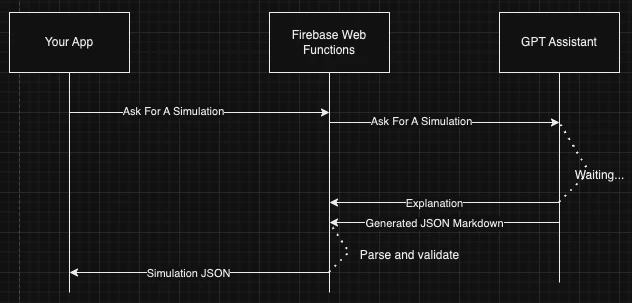
Your client is responsible for parsing the messages and extracting any generated JSON therein. When I was doing this I had a regex that looked for json markdown and assumed that was the content I asked for.
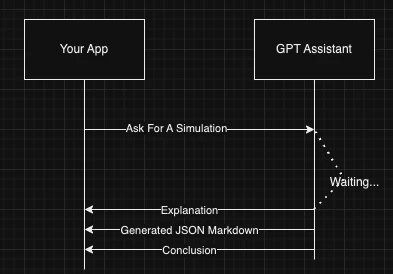
Step 1: Move our communication layer server side
This provides a gateway where we can more tightly control how we are querying. Even better, it provides a standard place to sanitize the data we are generating, and it gives us much better access controls. The client does not need to know any of our OpenAI identifiers, and the Firebase web function can manage permissions logic. At this point our communication flow looks like:
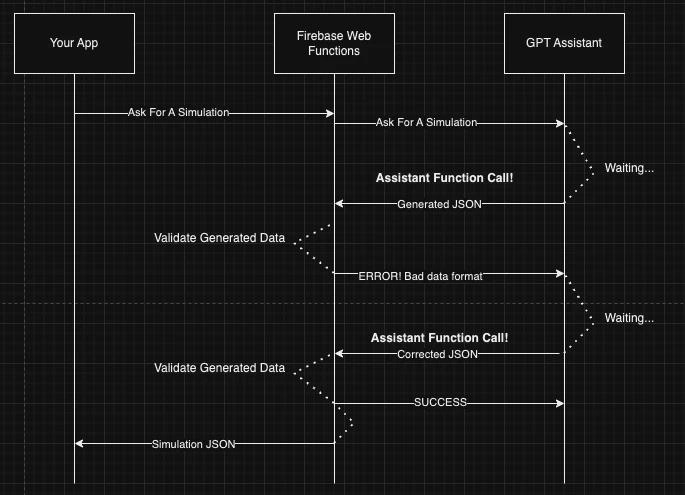
Step 2: Make use of Assistant Functions
Parsing messages to extract dubious JSON blobs is not an ideal way to operate. Assistant Functions provide a really nice mechanism for passing specifically formatted data where it needs to go. It also provides a mechanism for correcting validation errors. I have been using pydantic to generate JSON Schemas, which can be directly supplied as function definitions. Pydantic provides useful validation messages at parse time, and we can pass those validation messages back to the GPT Assistant to make corrections as shown here:
Step 3: Make it reactive
At this point we are making a three minute long GET request, which is bad form! Our app is reactive, this should be too! We are already taking advantage of the streaming capabilities of Firestore, and our cloud functions already have access to it. Let's take advantage of that!
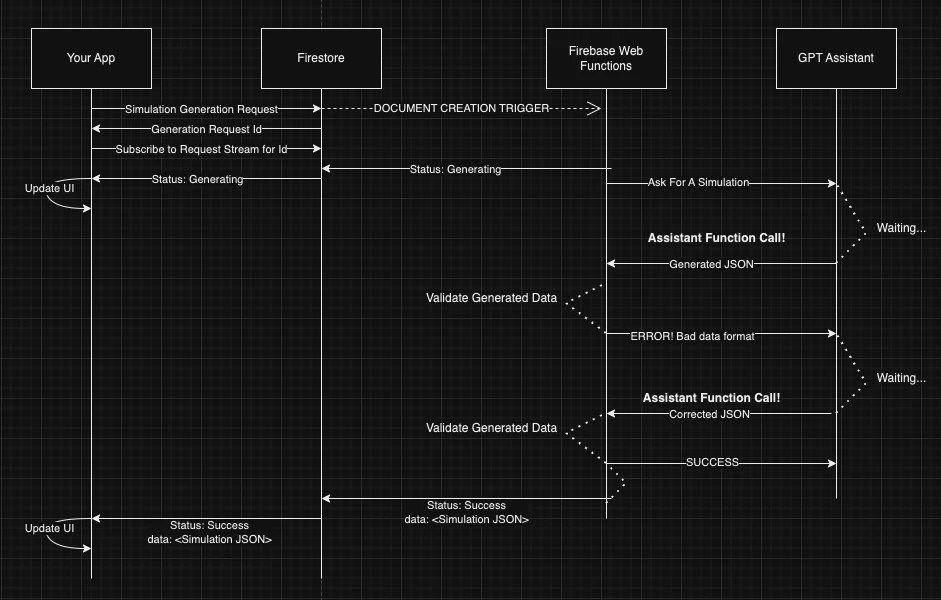
We begin storing a “Simulation Generation Request” in Firestore that has all the data needed to know what to generate. A Document Creation trigger runs any time a new “Simulation Generation Request” is created, which sets off our actual generation routine.
The client can listen to the stream of status updates related to that request (or fire and forget).
Advantages
Data Flow - the client can queue a request and listen for updates independently.
Data sanitation - all data available to the client is sanitized and validated on the server side.
Security - The web function can sanitize any requests being made by the client and can read or write to Firestore with permissions independent of the user.
Data availability - All generated data is stored and available for reuse.
Replay - Because our app is just listening to a requestId, we can sub in any request Id we want during the development process
Disadvantages
Latency - making our data travel through Firestore generally adds a second or two between the result being generated and the client getting the update. This was not significant for our large Simulation generation queries (sometimes lasting a minute or two).
Cost - we are using web functions that are mostly just polling openAI, and we are storing data in Firestore, which has associated costs.
Conclusion
This is a nice setup. It keeps your client isolated from the mechanics of generation, and provides a convenient streaming interface for the generated data. It allows us to keep our secrets safe, and to restrict access to our generation features. The added costs of the Google infrastructure are small compared to the costs of generating our Simulations via GPT-4.